
Objetivo del taller
En este taller aprendemos cómo construir una inteligencia artificial, o sea, un programa informático que usando diferentes técnicas de aprendizaje por refuerzo (reinforcement learning) nos permite jugar a diferentes juegos sencillos, además de ver otras implementaciones más complejas de esta misma técnica que han permitido vencer al campeón mundial de GO con el programa AlphaGO, conseguir niveles de élite en e-sports o competiciones profesionales de videojuegos como League of Legends (LOL), Dota2 o Starcraft world. Además, apuntamos potenciales oportunidades para aplicar estas mismas técnicas en la robótica y la industria hoy en día.
Todo ello de forma práctica, con ejemplos y para cualquier persona aunque no tenga conocimientos de programación lo pueda entender.
Base conceptual
El aprendizaje por refuerzo es una área dentro de la inteligencia artificial en la cual el objetivo es aprender en base a los errores que vamos cometiendo. La manera más sencilla de ejemplificar sería con un juego. Si por ejemplo estamos jugando al Mario Bros, somos el agente, iremos recibiendo recompensas positivas cada vez que consigamos una moneda, por ejemplo, sin embargo recibiremos una recompensa negativa si nos encontramos con alguna seta o caemos por un hoyo. Una vez acabada la partida, ganemos o perdamos tendremos que hacer un análisis de cuáles han sido las acciones que hemos realizado y nos han beneficiado y cuales son aquellas que no lo han hecho. Con este entrenamiento, la próxima vez que juguemos a la partida habremos aprendido que deberíamos hacer y qué no.
Mediante este ejemplo puede aproximarse el concepto de aprendizaje por refuerzo, fig.1. Hay una serie de elementos que es importante conocer a la hora de trabajar y comprender este campo.
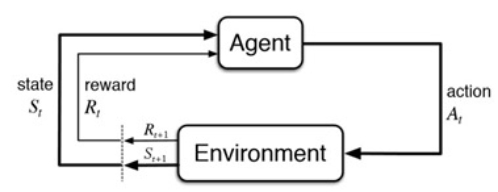
En primer lugar se encuentra el agente, es el elemento principal que realiza las acciones y se mueve por el entorno. Cada vez que realiza una acción obtiene dos informaciones; el nuevo estado, por ejemplo si vamos andando por baldosas nos indicaría que estamos en la baldosa de la derecha si hemos realizado la acción de ir a la derecha; y además nos devuelve una recompensa, esta nos indica cómo de buena, mala o neutra ha sido nuestra acción.
El conjunto de acciones que vamos realizando nos dan lugar a una política, el objetivo de esta será maximizar el número de recompensas que obtenemos al final del recorrido o entorno.
Cuando nos movemos por un entorno puede suceder que encontremos un camino que nos lleva satisfactoriamente hacia el punto final, sin embargo, también puede suceder que haya más de un camino que nos lleve hacia ese punto y que incluso nos permite obtener mejores recompensas. Por esta razón cuando el agente se encuentra en un entorno, a la hora de realizar una acción debe buscar un equilibrio entre la exploración, descubrimiento de nuevos caminos, y la explotación, usar el conocimiento previo para tomar las acciones futuras. A este equilibrio se le conoce como política Є-greedy.
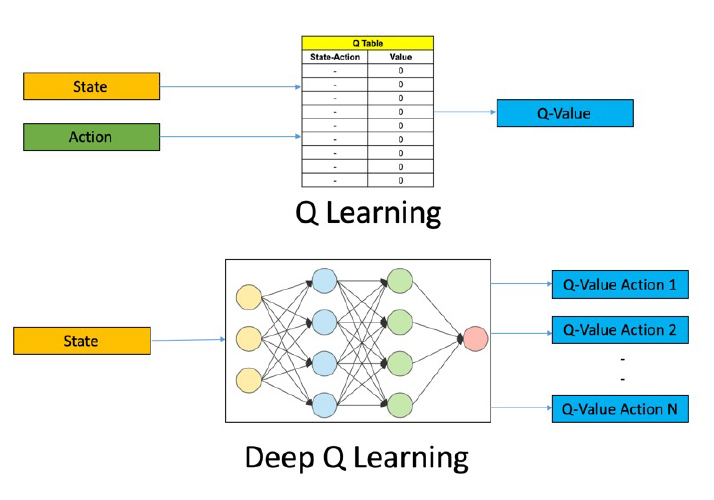
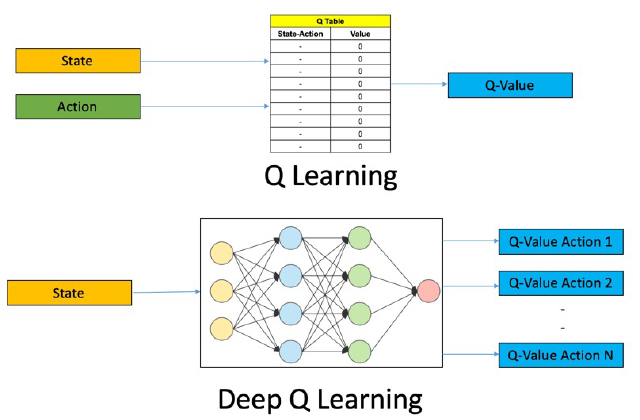
Uno de los métodos que se emplea en Reinforcement Learning es el conocido como Q-Learning. Este algoritmo durante el entrenamiento memoriza el estado de origen y la acción realizada junto con la recompensa obtenida y lo almacena en una tabla, fig.2. Sin embargo en caso de querer trabajar con videojuegos, en los cuales los datos de entrada son multidimensionales, dependiendo de los píxeles que haya en la imagen, o en caso de trabajar con entornos muy grandes, el hecho de almacenar los datos en una tabla no es sostenible. Con el fin de solventar estos problemas, en 2015 Deep Mind usó Deep Learning, concretamente una red convolucional para aplicarla junto a Q-Learning.
Hay una serie de entornos creados por OpenAI que pueden ser usados por el público en general con el fin de interactuar con el mundo del aprendizaje supervisado. https://gym.openai.com/
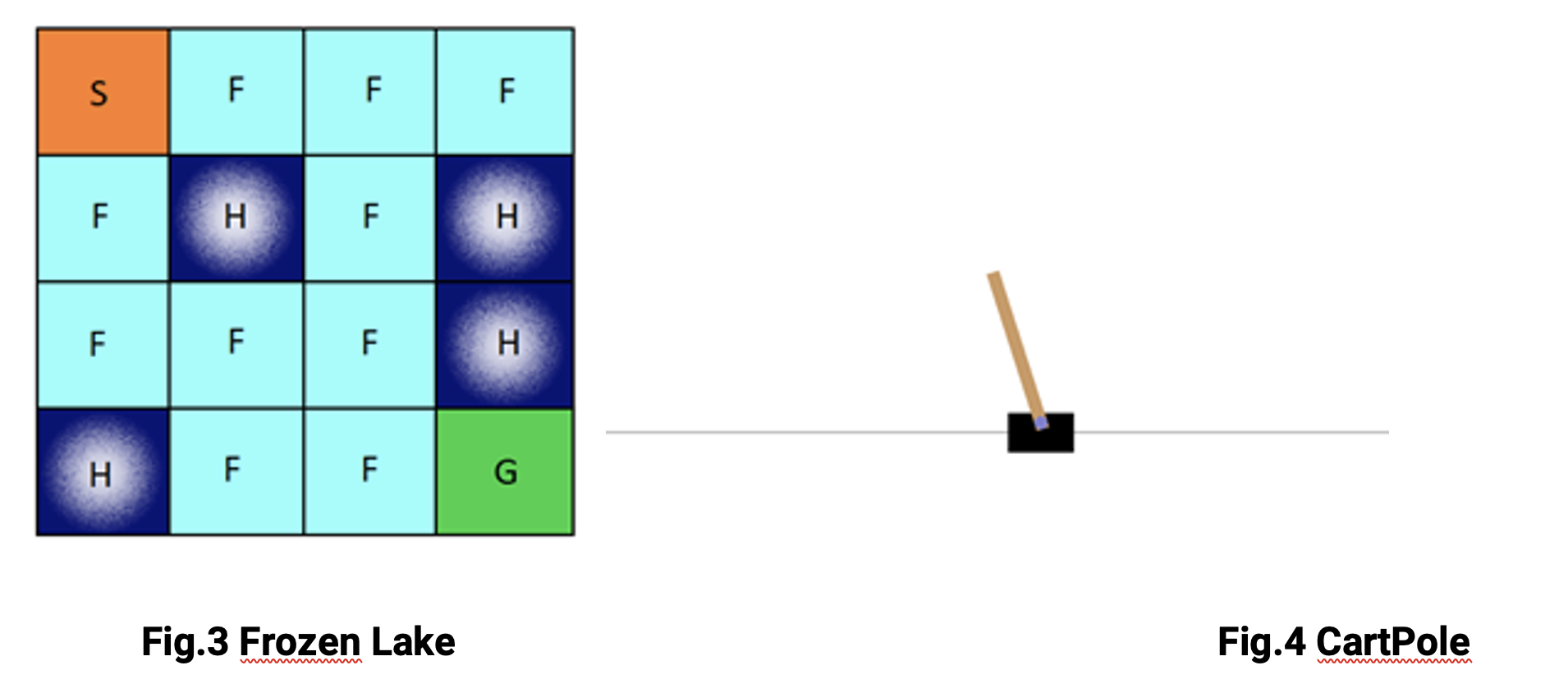
Entre ellos destacan Frozen Lake (fig.3) , un entorno estocástico, por lo tanto un entorno en el que tomando la acción de ir hacia arriba es posible que acabemos en otra posición, debido a que el hielo resbala y el CartPole (fig.4), un entorno en el cual el objetivo es aplicar el concepto del péndulo inverso, es decir mantener un palo en posición vertical.
Descripción y herramientas
En este taller se han empleado y explicado en más profundidad los conceptos mencionados usando ejemplos sencillos. Mediante una Google Colaboratory (https://colab.research.google.com/) se presentan los ejemplos anteriormente mencionados, Frozen Lake y Cartpole de los cuales se dispone gracias a la librería gym de OpenAI (https://gym.openai.com/), el lenguaje de programación usado es Python y el entorno para modelizar los programas y hacer los ejercicios es Jupyter Notebook. En este ejercicio práctico se usan tanto conceptos propios del Machine Learning, como es el algoritmo Q-Learning para implementar el Frozen Lake, como el estado del arte en el que se mezcla tanto Machine Learning como Deep Learning usando el Deep Q-Learning para su aplicación en el CartPole.
Además, se imparte el taller apoyándonos en la plataforma Eduflow (https://www.eduflow.com/) como espacio de trabajo, y la comunidad de Saturdays.ai (https://community.saturdays.ai/) para consultar dudas y continuar el aprendizaje, realizando el streaming en Youtube.
Puedes ver el taller completo aquí:
