



Presentación del taller
El pasado 21 de Enero tuvo lugar el taller “Conviértete en dibujos animados usando Inteligencia Artificial” de la mano de Epitech y Saturdays. En este taller se exploraron las bases teóricas y prácticas de los modelos generativos, en particular de las redes GAN en la tarea de transferencia de estilo.
Los objetivos principales del taller fueron entender los fundamentos teóricos de los modelos generativos, la transferencia de estilo, y la implementación de una red GAN que permita realizar una transferencia de estilo con carácter general.
Conceptos teóricos
La Inteligencia Artificial (IA) aplicada a la visión por computador ha llegado para quedarse, y muestra de ello es el gran abanico de filtros que proporcionan algunas redes sociales como Snapchat, Instagram, o TikTok, que permiten distorsionar la realidad captada por la cámara.
Ya sea como entretenimiento o con fines comerciales, en los últimos meses han proliferado las aplicaciones que permiten convertir cualquier foto en una obra de arte, en un personaje de anime o en un personaje de dibujos animados. Esta misma tecnología está siendo utilizada por grandes empresas tecnológicas como Adobe para el desarrollo de la siguiente generación de Photoshop, por Disney para la creación de nueva tecnología de animación mucho más realista y con un menor consumo de recursos, o por IBM para la generación sintética de imágenes que permitan aumentar los limitados conjuntos de datos utilizados para el entrenamiento de modelos de inteligencia artificial mucho más complejos.
El conjunto de todas estas tecnologías que lidera el estado del arte y presenta nuevas aplicaciones mes a mes se engloba dentro de un campo mucho mayor: los modelos generativos.
Para entender el contexto en el que están contenidos estos modelos deberemos distinguir entre los modelos discriminativos y los modelos generativos.
Los modelos discriminativos son modelos cuya función principal es la de llevar a cabo tareas de clasificación. A partir de un conjunto de características X, como pueden ser los píxeles de una imagen, el modelo tratará de clasificarla en una clase de entre las disponibles Y, proporcionando no sólo la clase a la que pertenece sino el grado de confianza de esta clasificación. Es decir, este tipo de modelos aprenderán la probabilidad condicional P(Y|X).
Por contrapartida, los modelos generativos son modelos cuya función principal es la de generar a partir de un conjunto de números aleatorio (ruido), un conjunto de características lo suficientemente bueno como para poder representar la clase a partir de la cual ha sido entrenado. Es decir, este tipo de modelos aprenderán la probabilidad condicional P(X|Y). Esta señal de ruido aleatorio será la encargada de proporcionar la diversidad al modelo, para evitar que siempre genere el mismo tipo de imágenes.
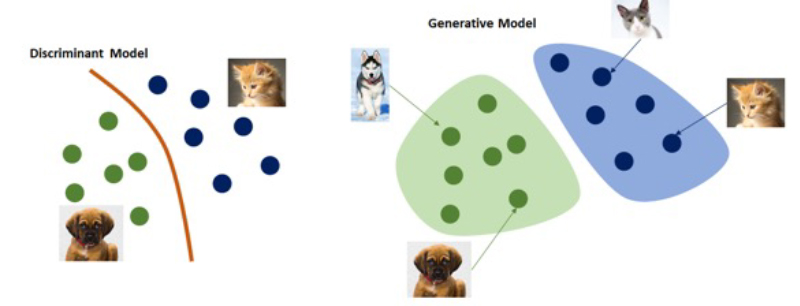
Pese a que existen distintos tipos de modelos de inteligencia artificial que pueden actuar como modelos generativos, sin duda uno de los más presentes en la literatura son las conocidas como Redes Generativas Adversarias (GAN).
Presentadas en el año 2014, las GAN llegaron para revolucionar el campo de la visión por computador, proporcionando los fundamentos de lo que sería el inicio del concepto de la creatividad en el contexto de la Inteligencia Artificial, y la base para el desarrollo de numerosas tecnologías con un gran impacto en ámbitos interdisciplinares como la conducción autónoma, la medicina, la agricultura o el diseño gráfico.
Una arquitectura GAN se compone principalmente de dos redes neuronales individuales: el generador y el discriminador. Mientras que la red generativa tratará de generar los resultados falsos más realistas posibles a partir de ejemplos de referencia, la red discriminativa tratará de distinguir estos resultados falsos de las imágenes reales.
Una analogía que trata de facilitar el entendimiento del funcionamiento de estas redes es la del falsificador y el experto de arte. La red generativa es el equivalente a un falsificador de cuadros: tratará de crear las réplicas más realistas posibles hasta que sean indistinguibles de los cuadros realistas, y consigan engañar al experto. Por su parte, la red discriminativa es el equivalente a un experto en arte: tratará de distinguir con la mayor precisión posible las falsas réplicas de los cuadros originales. En el proceso de entrenamiento, ambas redes competirán entre sí para tratar de ir por delante de su contrincante (por este motivo reciben el nombre de redes adversarias). El entrenamiento finalizará en el momento en el que el generador consiga engañar al discriminador en la mayoría de las ocasiones.
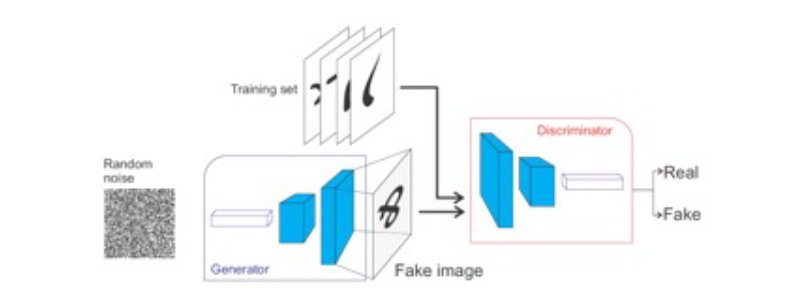
En realidad, tras finalizar el proceso de entrenamiento iterativo, la red discriminadora deja de ser necesaria, pues la red generadora ya ha aprendido la distribución de los datos originales, y puede utilizarla para la síntesis de nuevas imágenes. Los pesos entrenados de la red generadora serán almacenados y utilizados para la síntesis de nuevas imágenes a partir de ruido aleatorio.
Algunas modificaciones más avanzadas han sido presentadas desde la propuesta de las arquitecturas más básicas de GAN. Modelos como Pix2Pix (2016) o StyleGan (2019) permitieron que las GAN no sólo fueran capaces de generar nuevas realidades imaginadas, sino de utilizar una referencia para ello. De este modo, imágenes en blanco y negro podrían recuperar su color, imágenes tomadas de día podían simular haber sido tomadas de noche, cuadros paisajísticos podían tomar el aspecto de fotografías, etc.
Una de los eventos al respecto más destacables, es cuando recientemente el laboratorio de inteligencia artificial de NVIDIA (empresa líder en IA), liberó públicamente un modelo interactivo conocido como GauGAN capaz de transformar mapas semánticos en imágenes realistas. No sólo los resultados son muy cercanos a la realidad para cada una de las categorías, sino que se conserva el contexto semántico global de la imagen.
Estos nuevos modelos sentaron la bases de lo que se conoce como transferencia de estilo; la capacidad de trasladar el estilo de una imagen al contenido de una segunda.
Herramientas y resultados del taller
A lo largo del taller se utilizó la plataforma de trabajo Google Colab y el lenguaje de programación Python. Mediante algunas arquitecturas pre-entrenadas, los participantes fueron capaces de utilizar sus propias imágenes de contenido y estilo en la tarea de la transferencia de estilo.
A continuación se presenta uno de los resultados obtenidos por uno de los participantes:

Puedes ver el taller completo aquí:
