

Presentación del taller
El día 3 de junio Saturdays.AI junto con Epitech realizamos el taller “Combate el estrés con Inteligencia Artificial”. Durante este taller se exploran las bases teóricas y prácticas del machine learning, en particular de modelos de predicción como son los árboles de decisión, los bosques aleatorios y las regresiones lineales.
Imaginémonos que nos encontramos en época de exámenes, que suele ser bastante estresante para muchos, y decidimos que durante todo el día vamos a estar estudiando porque no llevamos muy bien el próximo examen. Le dedicamos tres horas seguidas de estudio por la mañana sin descansar, nos vamos a preparar la comida porque nos ha entrado hambre, pero aun así seguimos pensando en que tenemos que volver rápido al escritorio. Después de comer nos volvemos a sentar delante de nuestros apuntes y estamos otras 3 horas, pasadas esas 3 horas sentimos cierta molestia física y mental. ¿Qué puede estar pasando? Que nos estemos estresando demasiado por el examen y por culpa de eso estemos estudiando sin descanso, cosa que no es buena para la salud.
Ahora imaginémonos que volvemos a empezar el mismo día, pero tenemos un smartwatch puesto, nos decidimos a estudiar tres horas seguidas pero cuando llevamos 1 hora, vibra el smartwatch, le echamos un ojo para ver que dice y vemos que nos está avisando de que estamos aumentando el nivel de estrés y que sería conveniente descansar 10 minutos y una vez descansado el cuerpo y la mente estarán en mejor estado para seguir estudiando.
Lo que pretendemos con este taller es observar cómo a partir de datos de diferentes dispositivos se puede predecir el nivel de estrés para casos como el del ejemplo.
Los principales objetivos de este taller son entender y aprender a usar un conjunto de datos, prepararlo adecuadamente para ser utilizado para entrenar un modelo y por último saber crear un modelo de predicción que se ajuste a los datos vistos.
Conceptos teóricos
Cada vez más gente utiliza un smartwatch, prueba de ello es que van saliendo más modelos y mejores. Incluso hay algunos que miden el oxígeno en sangre. Para encontrar un reloj inteligente que cuide tu salud no hace falta ir a los que más cuestan, seguro que la mayoría conocéis a alguien que tenga una mi band, con eso es suficiente para tener una idea de cómo nos pueden ayudar estos aparatos a mejorar nuestra salud.
Ahora bien, cuando hablamos de wearables no solo hablamos de smartwatch sino que hay muchos más dispositivos, los que vayáis en bici seguro que conocéis los sensores de frecuencia cardíaca que se usan, para los demás, son una especie de pulsera o cinta que se suele poner como cinturón que mide con más exactitud tus pulsaciones cuando estás haciendo ejercicio.

Si a todos los datos obtenidos por dispositivos como estos les aplicamos la Inteligencia artificial podemos obtener grandes resultados que pueden ayudar a muchas personas.
Para entender los modelos que vamos a usar es importante entender antes que hay dos tipos de aprendizaje cuando hablamos de modelos. Podemos distinguir los dos siguientes:
- Aprendizaje supervisado
- Aprendizaje no supervisado
¿Cuál es la diferencia entre los dos tipos? Un aprendizaje supervisado es aquel en el que se usan diferentes técnicas para predecir una variable en concreto mientras que el aprendizaje no supervisado es aquel en el que los modelos realizados obtienen nueva información y no predicen una variable. SI lo que se desea es predecir el resultado de una variable, en este caso el nivel de estrés en el que la persona se encuentra tenemos delante un problema de aprendizaje supervisado mientras que si lo que deseamos es agrupar las muestras por similitudes hablamos de no supervisado y en específico podríamos hablar de una técnica de clustering. El clustering se encarga de agrupar las muestras siguiendo algún criterio establecido, normalmente distancia o similitud. Para entender el clustering mejor podemos ver la siguiente imagen.
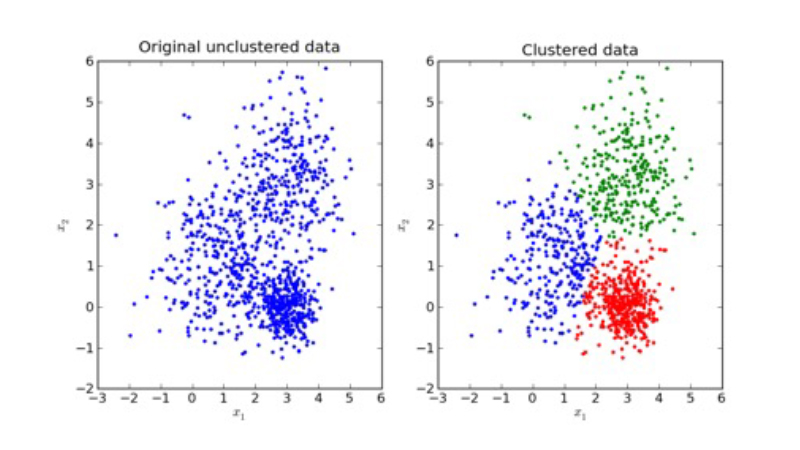
En este taller se trabaja con aprendizaje supervisado ya que el propósito de este taller es clasificar el sujeto según los datos vistos y por lo tanto es un problema de clasificación en el que la intención es predecir la variable que nos indica el nivel de estrés que está sufriendo el paciente. Para ello se usan diferentes modelos, los más conocidos son los árboles de decisión y los bosques aleatorios. ¡Para ver con exactitud cómo funcionan con los datos de los wearables te recomendamos mirar el taller!
Herramientas y resultados del taller
A lo largo del taller se utilizó la plataforma de trabajo Google Colab y el lenguaje de programación Python. Mediante la creación de algunos modelos de predicción los participantes pueden predecir el nivel de estrés en el que se pueden encontrar. Aunque en el taller también se observa cómo dependiendo de los datos que se usan para entrenar los modelos el resultado de la predicción es más acertado o menos.
Puedes ver el contenido completo de este taller aquí:
